
EL PROBLEMA
El objetivo general de este proyecto es la investigación e implementación de modelos computacionales que permitan traducir imágenes y sonidos en significado y acciones. Este complejo problema abarca la visión por computador, el procesado de señales auditivas, el análisis de escenas a partir de señales de audio y vídeo, el aprendizaje automático, y la robótica. En concreto, existen numerosos problemas de análisis de imagen/vídeo potencialmente útiles en aplicaciones en donde se requiere una interacción humano-robot más fluida, natural y socialmente aceptable. Por ejemplo, un robot humanoide podría querer acercarse a una persona y preguntarle si necesita ayuda. Para ello, debe conocer la forma de cortesía adecuada (tú vs usted), para lo cual necesitaría un método de estimación de la edad a partir de las imágenes y sonidos que recibe (a una persona clasificada como «joven» podría tratarla de «tú», mientras que a una persona clasificada como «mayor» podría tratarla de «usted»). Por otro lado, de cara a seguir una conversación grupal de modo natural, un robot debería ser capaz de orientar su cabeza de modo adecuado hacia la persona o grupo de personas que esté hablando en ese momento. O, por citar un caso todavía más sofisticado, si un robot humanoide observa a un grupo de personas dirigiendo sus miradas hacia un cierto lugar del espacio, el comportamiento esperable es que sea capaz de seguir la mirada de las personas e identificar el objeto que están mirando. Todo ello con el objetivo de reproducir, de la forma más fidedigna posible, el comportamiento humano.
MÉTODOS EMPLEADOS
De cara a resolver todos los problemas concretos anteriormente mencionados, se han empleado redes neuronales profundas (deep neural networks) que, a partir de los propios datos, permiten resolver problemas complejos. En particular, distintos modelos de redes profundas se han usado para la estimación de la pose de la cabeza, la localización de puntos de interés en caras, la localización de puntos de interés en el cuerpo para estimar la pose corporal, la localización de puntos de interés en prendas de ropa, la estimación de la edad de una persona a partir de fotografías, y la estimación de la posición de objetos de interés a partir de las direcciones de mirada de los observadores.

Ejemplos visuales de tres de los problemas abordados: la localización de puntos de referencia (o landmarks) faciales, localización de landmarks corporales (para estimar la pose humana), y estimación de los tres ángulos que determinan la pose de la cabeza.Visual examples for three of the problems tackled: facial landmark localization, full-body pose estimation, and head pose estimation.
Todos estos problemas se han enfocado como problemas de regresión, es decir, la estimación de valores continuos (en oposición a discretos, como en el caso de los problemas de clasificación) a partir de las propias imágenes utilizando redes neuronales convolucionales. Otro problema abordado ha sido el del control del motor que mueve la cabeza de un robot a partir de fusionar información auditiva y visual. Para ello, se han empleado redes de neuronas recurrentes (especialmente adecuadas para procesado de secuencias temporales) y aprendizaje por refuerzo (que permite aprender a partir de la propia experiencia del robot con supervisión humana mínima).
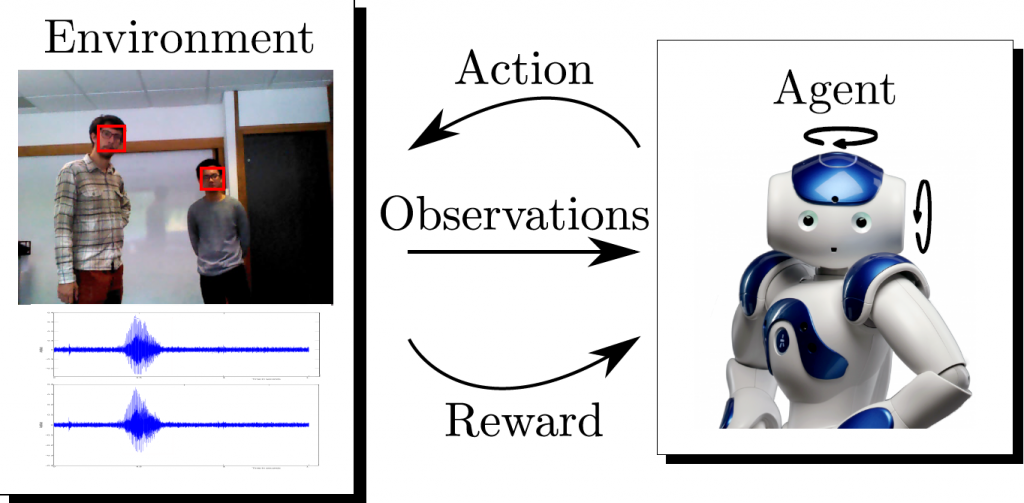
RESULTADOS
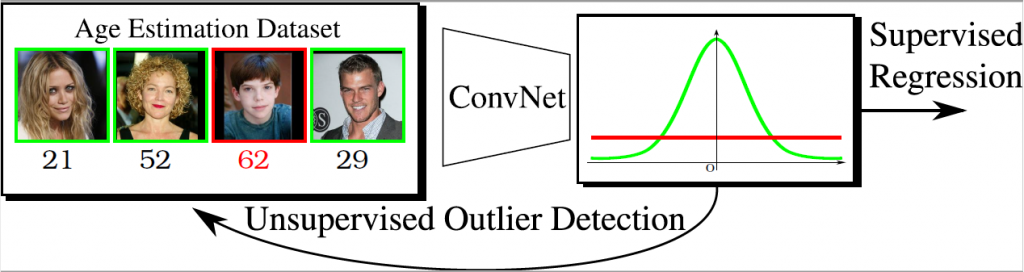
En relación a la estimación de la pose de la cabeza a partir de fotografías, el método desarrollado[1] mejoró a los métodos previamente existentes, estimando la pose de la cabeza con un error medio absoluto de 3.6o, y sin requerir ningún tipo de información adicional (p.ej. información de profundidad de la escena). Se diseñó e implementó un método de regresión robusta[2], capaz de proporcionar resultados competitivos en detección de landmarks faciales y de ropa, y en estimación de la edad y de la pose de la cabeza, incluso cuando el 30-50% de los datos de entrenamiento están contaminados con ruido.
Se presentó una novedosa aproximación para estimar la posición de objetos en el espacio, a partir de la dirección de la mirada de varios observadores, incluso si dicho objeto de interés se encontraba fuera del campo de visión de la cámara[3]. Se propuso una estrategia, basada en aprendizaje por refuerzo, para controlar los motores de la cabeza de un robot en entornos conversacionales[4],[5] a partir de la fusión de información visual y auditiva. Dicha estrategia permitió aprender al robot de modo autónomo, gracias al empleo de un entorno virtual que aceleró su aprendizaje (ahorrando la interacción directa durante horas con humanos). Finalmente, se realizó el estudio sistemático de varias técnicas de aprendizaje profundo aplicadas a problemas de regresión en visión por computador[6] (estimación de landmarks faciales y corporales, así como de la pose de la cabeza). Entre las principales conclusiones de dicho estudio metodológico cabría mencionar: la importancia clave del preprocesado de los datos (que en muchos casos tiene un impacto superior al introducido por cambios arquitecturales en la red), y el hecho de que las redes neuronales profundas de propósito general pueden competir con redes específicamente diseñadas para una tarea concreta (si son ajustadas de modo adecuado). Una red ajustada de modo adecuado puede llegar a mejorar su rendimiento en un 15% con respecto a la red de referencia.
PARTICIPANTES
Instituciones
Instituto Nacional de Investigación en Informática y Automática (Institut National de Recherche en Informatique et en Automatique, Inria, Francia). Trabajo realizado a través de un proyecto europeo ERC Advanced Grant titulado «Vision and Hearing in Action», cuyo investigador principal era el Dr. Radu P. Horaud, y financiado con 2.497.000€.
Investigadores
Dr. Pablo Mesejo como investigador postdoctoral senior (Inria Starting Researcher Position) en el equipo PERCEPTION (Interpretación y Modelado de Imágenes y Sonidos), liderado por el Dr. Radu P. Horaud, perteneciente al centro de investigación Inria Grenoble Rhône-Alpes (Francia).
REFERENCIAS
[1] Lathuilière, S., Juge, R., Mesejo, P., Muñoz-Salinas, R., and Horaud, R., «Deep Mixture of Linear Inverse Regressions Applied to Head-Pose Estimation», 28th IEEE International Conference on Computer Vision and Pattern Recognition (CVPR’17), 7149-7157, Honolulu, 2017
[2] Lathuilière, S., Mesejo, P., Alameda-Pineda, X., and Horaud, R., “DeepGUM: Learning Deep Robust Regression with a Gaussian-Uniform Mixture Model”, 15th European Conference on Computer Vision (ECCV’18), Munich, 2018
[3] Massé, B., Lathuilière, S., Mesejo, P., and Horaud, R., “Extended Gaze-Following: Detecting Objects in Videos Beyond the Camera Field of View”, accepted at the 14th IEEE International Conference on Automatic Face and Gesture Recognition (FG’19), Lille, 2019
[4] Lathuilière, S., Massé, B., Mesejo, P., and Horaud, R., “Deep Reinforcement Learning for Audio-Visual Gaze Control”, 31st IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’18), 1555-1562, Madrid, 2018
[5] Lathuilière, S., Massé, B., Mesejo, P., and Horaud, R., “Neural Network based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction”, Pattern Recognition Letters, Special Issue on “Cooperative and Social Robots: Understanding Human Activities and Intentions”, 2018
[6] Lathuilière, S., Mesejo, P., Alameda-Pineda, X., and Horaud, R., “A Comprehensive Analysis of Deep Regression”, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019