Deep learning techniques for computer vision and human-robot interaction

The problem
The general and final goal of this project is the investigation and implementation of computational models for mapping images and sounds onto meaning and onto actions. This challenging problem spans computer vision, auditory signal processing, audio scene analysis, machine learning, and robotics. In particular, I have collaborated mainly in image/video analysis problems that are potentially useful in applications where a more fluid, natural and socially acceptable human-robot interaction is required. For example, a humanoid robot might want to approach a person and ask if he/she needs help. To do this, it must know the appropriate form of courtesy (in Spanish, tú vs. usted; in French, tu vs. vous), for which we may need a method for age estimation from the images and sounds the robots receives. On the other hand, in order to follow a group conversation in a natural way, a robot should be able to orient its head in an appropriate way towards the person or group of people that is speaking at that moment. Or, to mention a more sophisticated case, if a humanoid robot observes a group of people directing their gaze towards a certain region in space, the expected behavior is that it is able to follow the people’s gaze and identify the object they are looking at. All with the aim of reproducing, as close as possible, human behavior.
Methods employed
In order to solve all the aforementioned problems, deep neural networks are employed. These techniques are able to solve complex problems learning directly from data. In particular, different deep models have been used for head pose estimation, facial landmark localization, full body pose estimation, fashion landmark location, age estimation, and the estimation of the location of objects of interest from the observers’ gaze direction.

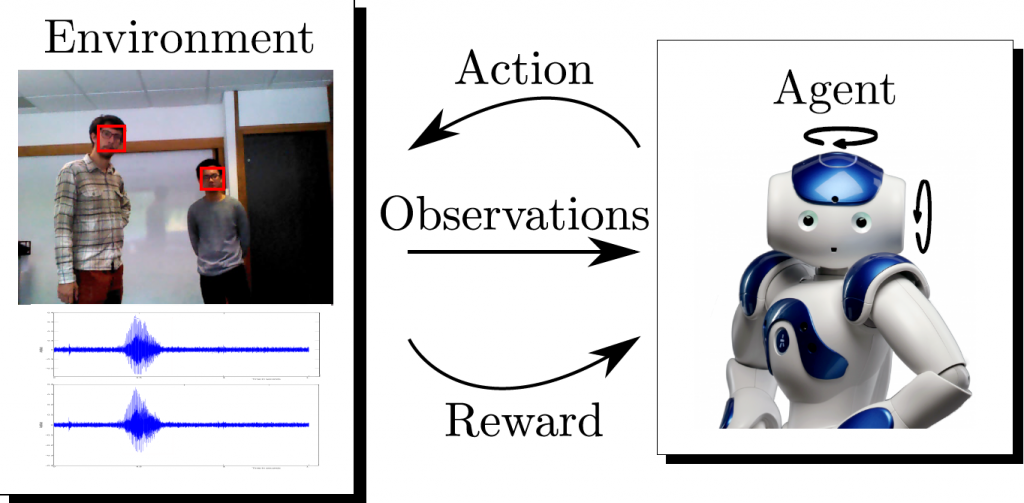
All these tasks have been approached as regression problems, that is, the estimation of continuous values (as opposed to discrete values, as in the case of classification problems) directly from images using convolutional neural networks. Another problem addressed has been the control of the motor that moves the head of a robot from fusing auditory and visual information. For this, recurrent neural networks (especially suitable for processing temporal sequences) and reinforcement learning (which allows learning from the robot’s own experience with minimal human supervision) have been employed.
Results
In relation to the head pose estimation problem, the method developed[1] improved prior approaches by estimating the head pose directly from photographs with a mean absolute error of 3.6 degrees, and without requiring any additional information (e.g. scene depth information). A robust regression method capable of providing competitive results in facial and fashion landmarks detection, and in age and head pose estimation, even when 30-50% of training data are contaminated with noise, was also designed and implemented[2].

A novel approach was presented[3]to estimate the location of objects from the gaze of several observers, even if the object of interest was outside the camera’s field of view. A strategy was proposed, based on reinforcement learning, to control the motors of a robot’s head in conversational environments, from the fusion of visual and auditory information[4],[5]. This strategy allowed the robot to learn autonomously with minimal supervision, thanks to the use of a virtual environment that accelerated its learning (avoiding hours of direct interaction with humans). Finally, the systematic study of several deep learning techniques applied to regression problems in computer vision[6] (namely, full-body and head pose estimation, as well as facial landmark detection) was carried out. Among the main conclusions of this methodological study we could mentioned: the key importance of data preprocessing (which in many cases has an impact greater than the one introduced by architectural changes in the network), and the fact that general-purpose deep neural networks (like ResNet-50 or VGG-16) can compete with deep networks specifically designed for a particular task (if they are adequately tuned). A properly adjusted network can improve its performance by 15% compared to its baseline.
Participants
Institutions
French Institute for Research in Computer Science and Automation (Institut National de Recherche en Informatique et en Automatique, Inria, France). Work developed within an ERC Advanced Grant entitled “Vision and Hearing in Action” funded by 2.497.000€ and whose principal investigator was Dr. Radu P. Horaud.
Researchers
Dr. Pablo Mesejo with an Inria Starting Researcher Position at the PERCEPTION team (Interpretation and Modeling of Images and Sounds), led by Dr. Radu P. Horaud, belonging to the research center Inria Grenoble Rhône-Alpes (France).
References
[1] Lathuilière, S., Juge, R., Mesejo, P., Muñoz-Salinas, R., and Horaud, R., “Deep Mixture of Linear Inverse Regressions Applied to Head-Pose Estimation”, 28th IEEE International Conference on Computer Vision and Pattern Recognition (CVPR’17), 7149-7157, Honolulu, 2017
[2] Lathuilière, S., Mesejo, P., Alameda-Pineda, X., and Horaud, R., “DeepGUM: Learning Deep Robust Regression with a Gaussian-Uniform Mixture Model”, 15th European Conference on Computer Vision (ECCV’18), Munich, 2018
[3] Massé, B., Lathuilière, S., Mesejo, P., and Horaud, R., “Extended Gaze-Following: Detecting Objects in Videos Beyond the Camera Field of View”, accepted at the 14th IEEE International Conference on Automatic Face and Gesture Recognition (FG’19), Lille, 2019
[4] MLathuilière, S., Massé, B., Mesejo, P., and Horaud, R., “Deep Reinforcement Learning for Audio-Visual Gaze Control”, 31st IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’18), 1555-1562, Madrid, 2018
[5] Lathuilière, S., Massé, B., Mesejo, P., and Horaud, R., “Neural Network based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction”, Pattern Recognition Letters, Special Issue on “Cooperative and Social Robots: Understanding Human Activities and Intentions”, 2018
[6] Lathuilière, S., Mesejo, P., Alameda-Pineda, X., and Horaud, R., “A Comprehensive Analysis of Deep Regression”, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019